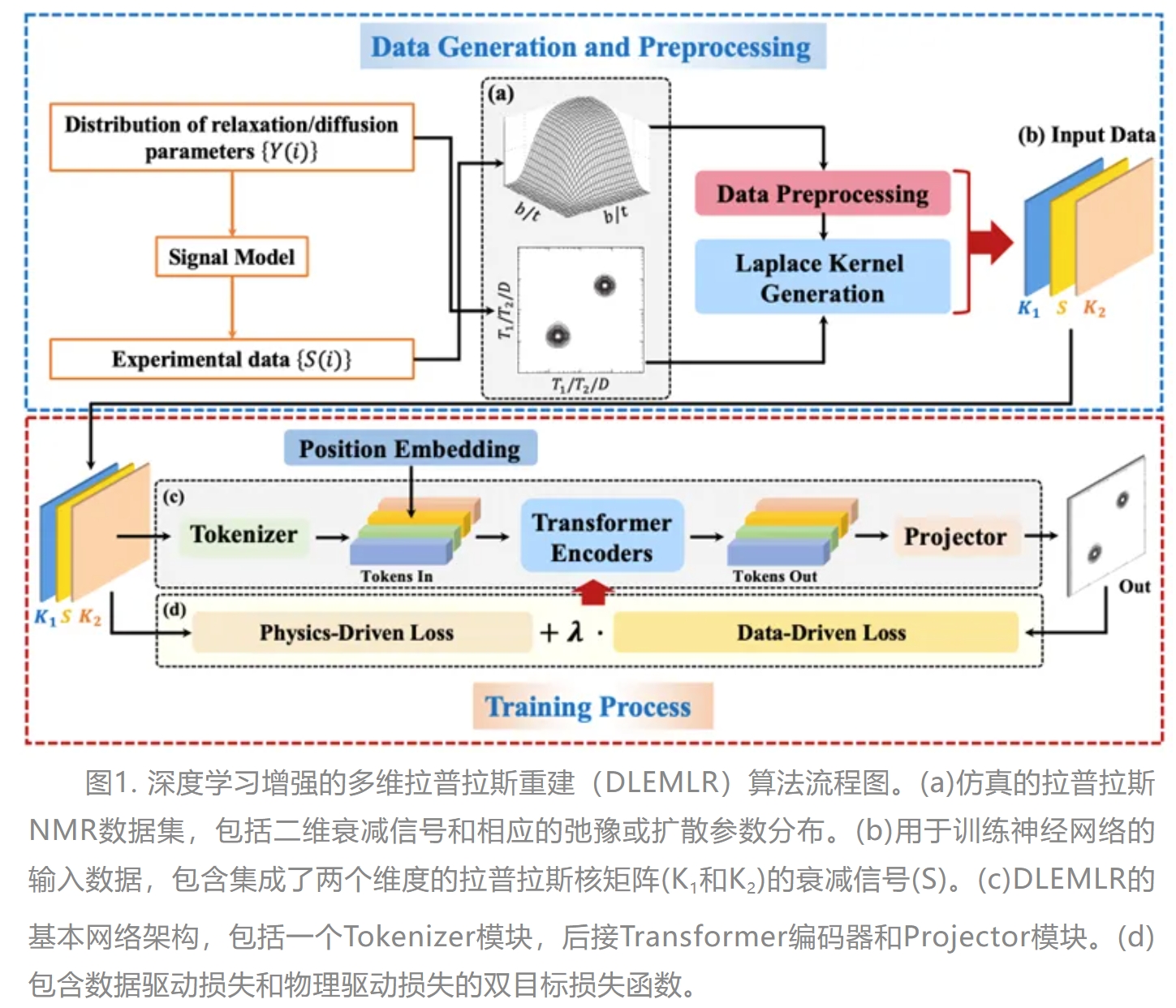
厦大陈忠教授团队JACS:基于深度学习的Laplace NMR波谱重建

拉普拉斯核磁共振波谱(Laplace NMR spectroscopy)技术通过检测与分子动力学和自旋相互作用相关的扩散或弛豫等信息,为研究分子的化学结构和物理环境提供了一种强大的工具,因此被广泛应用于化学、材料科学、生物医学、食品科学等多个领域。然而,拉普拉斯NMR波谱的有效性在很大程度上依赖于数据后处理算法从实验采集的指数衰减信号中提取弛豫时间、扩散系数等信息,如拉普拉斯反演(ILT)。由于ILT问题本质上是不适定的,因此很难进行令人满意的拉普拉斯NMR数据处理和重建,特别是对于二维拉普拉斯NMR实验。传统的拉普拉斯NMR数据处理算法通过人为附加不同的约束来限制解的空间,以得到符合预期的结果,但繁琐的正则化参数调整和冗长的优化迭代过程导致许多实际问题依然未解决,在二维甚至更多维的场景中解的病态性以及对噪声的敏感性面临着更严峻的挑战。为了解决该问题,厦门大学陈忠教授团队将物理信息嵌入仿真数据驱动的神经网络模型中,在国际上首次提出基于深度学习的多维拉普拉斯磁共振快速重建算法(DLEMLR),克服拉普拉斯反演的病态性及提高重建谱图的分辨率,并将重建时间缩短至秒级。
深度学习旨在识别训练数据集中的基本模式和内在关系,并利用这些信息对未知的数据进行预测。然而,由于仪器机时和样品种类的限制,构建一个庞大的拉普拉斯NMR训练数据集是一件不切实际的事情,因此DLEMLR通过前向物理模型生成仿真数据集来训练神经网络解决拉普拉斯逆问题。DLEMLR的基础架构为简化后的视觉Transforme (ViT)网络,包含多层感知机(MLP)和多头注意力机制(MHA)。在输入网络前,二维衰减信号与拉普拉斯核矩阵(如与T1弛豫时间相关的1-e-t/T1,与T2弛豫时间相关的e-t/T2,以及与扩散系数相关的e-bD)集成,随后被划分为小块,并在每个小块中融合嵌入正弦位置编码信息。随后,Tokenizer模块将每个小块压缩成表征弛豫或扩散过程相关的物理属性和高维特征信息的序列。在Transformer编码器中,MHA模块进一步计算这些特征序列之间的相关性,使模型能够高效地整合所有位置的信息。最后,Projector模块生成所有高维特征序列的综合表示,从而得到所需的二维拉普拉斯NMR波谱。此外,作者引入包含物理驱动损失项和数据驱动损失项的双目标损失函数,以提高结果的鲁棒性和与实验数据间的一致性。其中数据驱动损失是网络输出f(S;θ)与理想分布谱F之间的误差,增强了不同组分谱峰位置的准确性。然而,仅依靠数据驱动损失容易使模型忽略了实验样品中分子的固有物理属性,在真实实验数据不符合仿真数据分布时,模型产生的误差较大。因此,作者进一步引入物理驱动损失估计网络输出与给定前向过程输入之间的关系。具体来说,DLEMLR的输出通过给定的拉普拉斯核矩阵(即K1和K2)经前向过程变换到二维衰减域中,随后由物理驱动损失函数计算生成的2D衰减信号K1f(S;θ)K2T与原始输入S之间的残差,从而使重建谱峰的物理属性(如线宽、峰高)与实际分布更加一致。
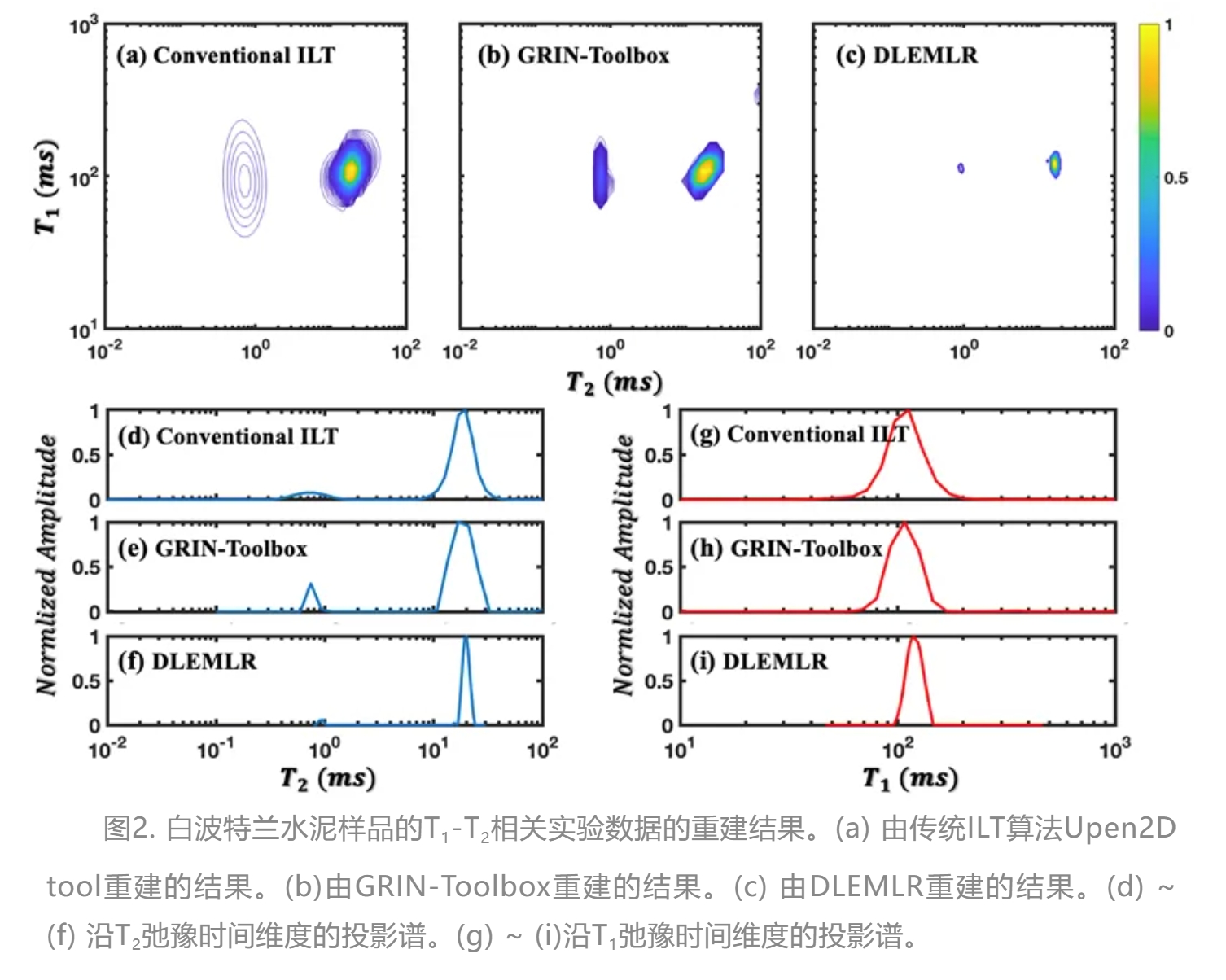
作者使用来自白色波特兰水泥样品的T1-T2相关实验数据评估DLEMLR的性能。图2展示了三种方法的结果,其中T2 ≈ 0.8 ms和20.0 ms处的两个谱峰在位置、峰高和振幅方面都表现出高度的一致性。白色波特兰水泥的孔隙结构受样品制备的影响,持续的水化过程导致其在储存时间内不断演变,这两个谱峰分别对应于水合物空间和毛细孔中的自旋群。如图2a和2b所示,Upen2DTool和GRIN-Toolbox重建结果中观察到的谱峰宽度较宽,表明谱峰位置存在较大的不确定性。Upen2DTool使用多参数Tikhonov正则化来改善结果的平滑度,导致图2a中所示的谱峰分布较宽且平滑。而 GRIN-Toolbox使用L1范数作为正则化手段提高结果的稀疏性,使谱峰分布相比Upen2DTool更为尖锐。相比之下,DLEMLR的结果以更高的分辨率和更低的不确定度显示了两个谱峰之间的差异性(图2c),更有利于不同成分谱峰的分离。为了更直观地进行对比,作者在图2d - 2i中提供了沿T1和T2弛豫时间维度的投影谱,峰值位置为估计的弛豫时间,而峰宽对应于结果的不确定性。这些投影谱能够更直观展示谱峰分辨率之间的差异,进一步证明了DLEMLR在获得高分辨率谱峰方面的优越性能。此外,DLEMLR 所需的处理时间,包括数据预处理和算法迭代,仅为 Upen2DTool和GRIN-Toolbox 所需时间的约10%。
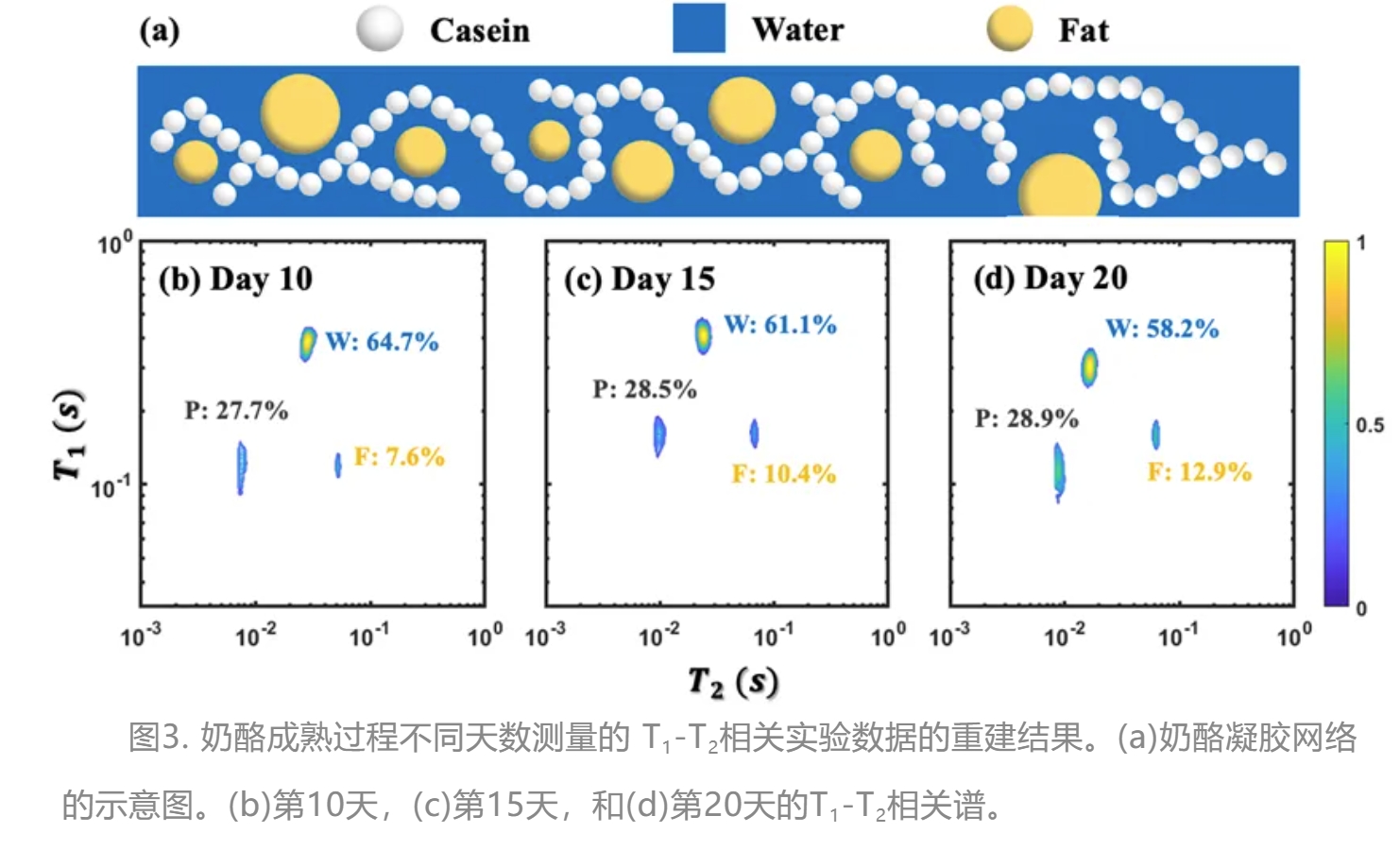
为了验证 DLEMLR 在处理复杂样品方面的有效性,作者使用了在奶酪成熟过程中第10天、第15天和第20天采集的三组T1-T2实验数据。如图3所示,在奶酪生产过程中形成了由水、液态脂肪和酪蛋白组成的奶酪凝胶网络,其演变受牛奶质量、牛奶类型、乳酶等因素的影响。如图3b,在成熟第10天测量的T1-T2相关谱中识别出了三个高分辨率信号。第一个信号(图3中标记为“W”),T1 ≈ 320 ms和T2 ≈ 40 ms,被归属为来源于水分子。第二个信号(图3中标记为“P”),T1 ≈ 160 ms和T2 ≈ 4 ms,被归属为酪蛋白中锁住的水分子,其T1弛豫时间和T2弛豫时间的比值约为40,表明化学交换是T2弛豫的一种高效机制。第三个信号(图5中标记为“F”),T1 ≈ 100 ms和T2 ≈ 70 ms,被归属为来源于液态脂肪。该脂肪峰表现出液态特性,其T1弛豫时间和T2弛豫时间的比值约为1,表明脂肪在奶酪中主要以液态形式存在。此外,对T1-T2相关谱中相对峰积分的分析表明,蛋白质和脂肪峰随着成熟时间的增加而成比例增加,而水分子峰则逐渐减少。实验结果表明DLEMLR方法在处理复杂样品方面具有显著的优势,能够提供高分辨率的成分分析和动态变化监测,对食品工业和其他相关领域具有重要的应用价值。