百“模”争鸣 国产AI芯片的机会来了?

集微网报道(文/李映)ChatGPT的爆火在全球范围内引发了一场AI“狂飙”,不仅让全球点燃了百模大战,也将算力芯片推到了战火最前线。
研究表明,每提高1%的算力,国家的数字经济和GDP分别将增长3.5‰和1.8‰。如此重要的战略地位,让算力之争已经不再是简单的商业、技术问题,已然上升至国家竞争的关键因素。
然而,全球90%以上的算力芯片被英伟达垄断,英伟达也被公认为全球AI淘金时代最大“卖铲人”。一方面,在供求失衡之际国外芯片“一卡难求”,价格暴涨;另一方面,美国接连祭出禁令限制高端AI芯片出口,英伟达为符合规定不断阉割性能,前不久英伟达更是宣布禁止用转译层在其他平台上跑其的CUDA软件。

更大范围、更具深远战略意义的AI芯片之争,显然将决定未来几十年的科技实力版图。在国际高端AI芯片面临被“逼退”之际,为立足于国家安全及自主可控,国产AI芯片无疑成为最佳替代选择。尤其是近年来在地缘政治影响下,我国本土AI芯片产业已取得一定发展成效,部分产品甚至可对标国际企业同类产品。尽管在算力、生态等层面还需要持续迭代,但产业链合力让国产芯片不断试错、提升我国在AI时代的竞争力已势在必行。
大模型加速赋能国产AI芯片迎来新窗口期
如果说2023年是AI大模型市场的百“模”争鸣,那么2024年则将成为国产大模型全面商业落地的元年,进入赋能千行百业的关键期。无数老将新贵正在加速扩展和落地应用场景,让AI大模型的能力从云端转化成为各种毛细血管的生产力,强力辐射至各行各业以及新业态的高质量发展。
随着国产模型性能的全面升级,先进的大模型能力也逐渐转化为落地实际场景的产品应用,强大的生成能力和涌现能力,带动大模型在办公、教育、医疗、工业制造等众多垂直行业的持续落地,AI2B与AI2C的需求天花板有望全面打开。
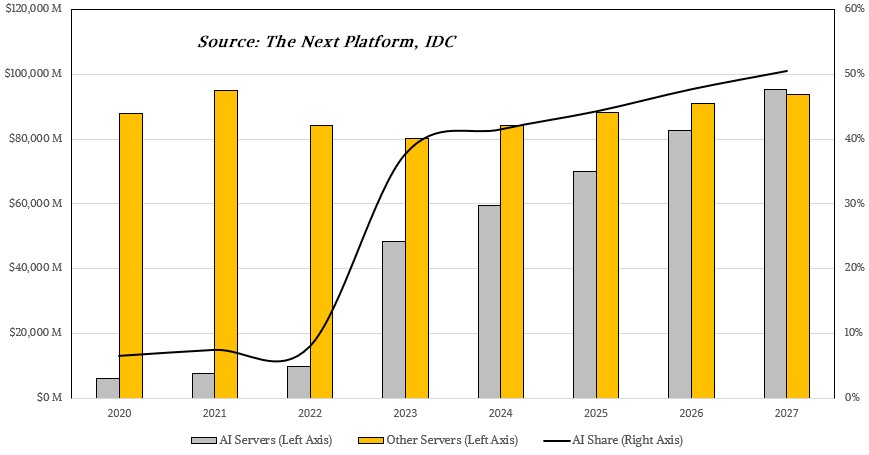
深入千行百业后,大模型所要具备的能力变得更加具象化和复杂化,需要全栈的技术支撑,而算力芯片是大模型的“燃料”。随着AI大模型的持续发展,对于算力的需求不断扩大。数据显示,2023年全球AI加速计算市场规模将达450亿美元。预计到2027年,全球数据中心AI加速芯片市场规模将达到4000亿美元。此外,为构筑自立自强的数字技术创新体系,国产AI芯片的自主可控需求凸显。在多重因素交织作用下,我国AI芯片行业发展迎来重要的战略性窗口和突破性的发展机遇。
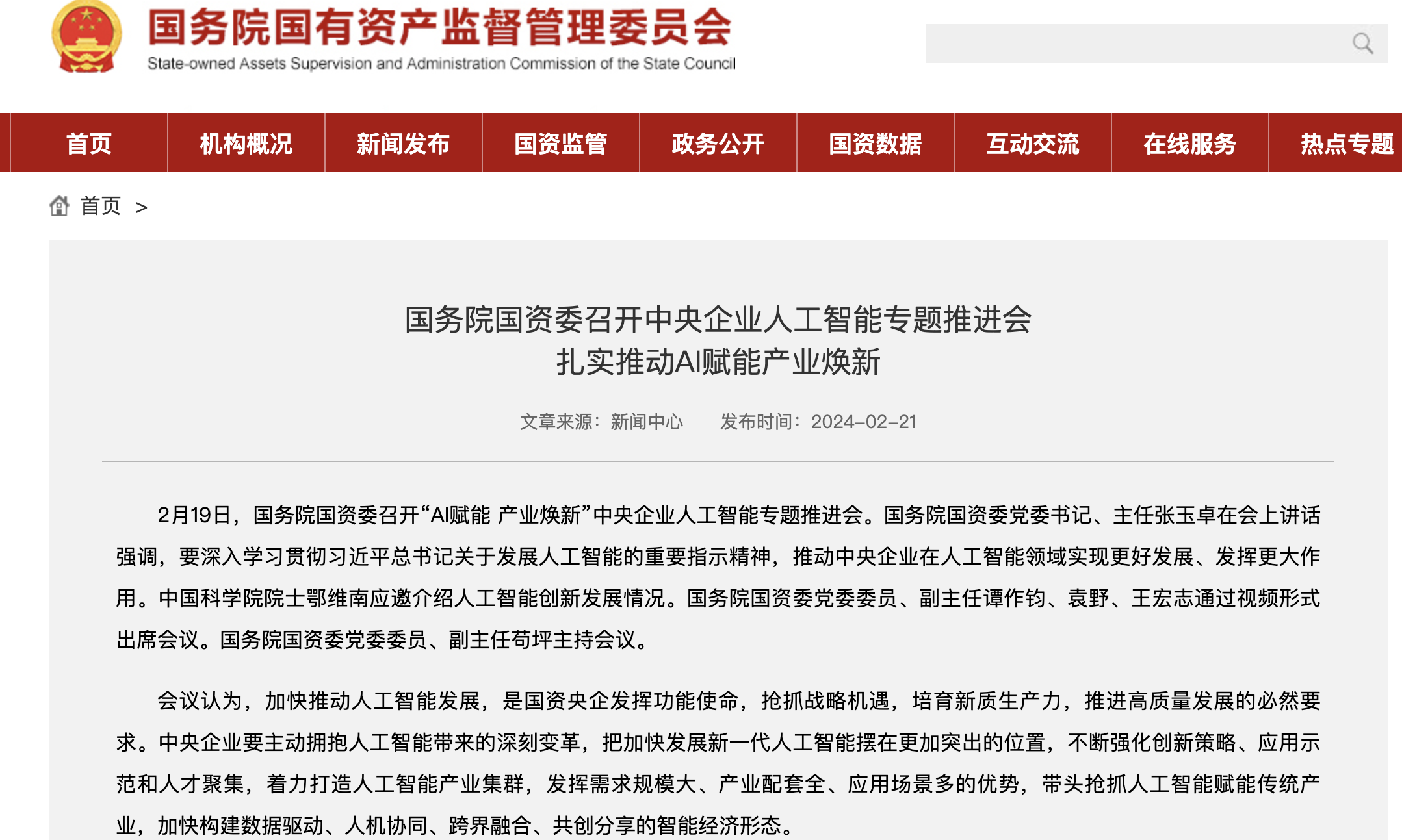
我国也制定了一系列扶持政策,鼓励AI芯片行业发展与创新。国务院国资委日前召开“AI赋能产业焕新”中央企业人工智能专题推进会中提出,开展AI+专项行动,打造从基础设施、算法工具、智能平台到解决方案的大模型赋能产业生态。前不久发布的政府工作报告也指出,要加强前瞻布局,加快提升算力水平,大力开展“人工智能+”行动,更好赋能千行百业,为加快培育和发展新质生产力注入澎湃动能。
国产AI芯片从可用到好用,谁能出鞘?
随着AI热潮持续升温,越来越多的厂商频频发力,不仅有亚马逊、微软、华为、百度、阿里等下游客户推动自研芯片开发,国内AI芯片也百花齐放,华为、摩尔线程、寒武纪、壁仞、天数智芯等也在各施奇招,争夺登上前往AI时代的一张新船票,为算力之争增添新动能。
大模型的升级迭代推动应用遍地开花之际,国产AI芯片厂商也迎来了更广阔的“试验田”。众所周知,国产芯片与英伟达等国际巨头相比,还在一个逐步成熟的阶段。如果说英伟达、英特尔和AMD等巨头之争是生态之争,那国产芯片的竞争就是性能之争。
而随着大模型发展如火如荼,训练算力需求有望扩张到原来的10倍至100倍,集群成为一大考验。国内AI芯片通过集群方式,能够实现算力的叠加,弥补性能上的差距,这种创新策略为国内在AI领域的技术发展提供了新的思路。
目前而言,国产AI芯片也大体呈现了三个梯队的格局。以产品性能、量产规模、拥有集群能力且已有场景落地等要素来考量,华为、海光、寒武纪、摩尔线程等公司可归为国产AI芯片的头部梯队。第二梯队则如壁仞、天数智芯、沐曦等,产品尚未规模落地。而一些起步不久的初创类芯片厂商,由于还在验证或量产阶段,产品仍在打磨阶段。
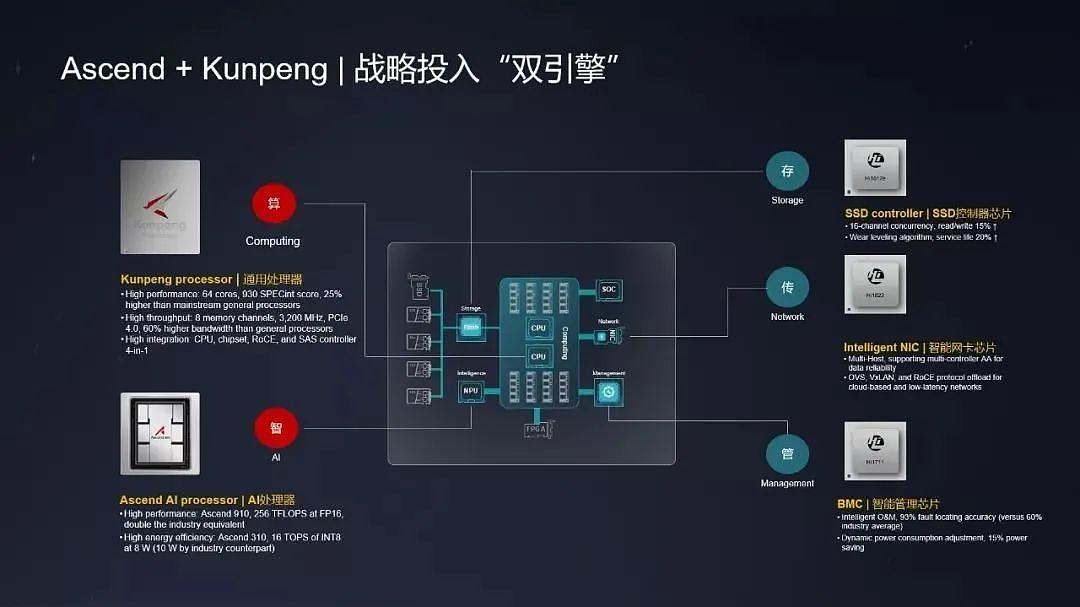
以华为为例,华为在去年发布了全新达芬奇架构的昇腾AI计算集群——Atlas900 SuperCluster,据了解该AI集群支持超万亿参数的大模型训练,采用全新的智算交换机以及超节点架构。在软件生态层面,华为推出了openEuler开源OS以及配套的数据库、中间件,涵盖从硬件、架构、框架、应用、开发运维工具等全产业链条,成为国产AI芯片的一支生力军。华为董事、ICT产品与解决方案总裁杨超斌在华为中国合作伙伴大会2024上表示,鲲鹏、昇腾逐步成为数智化转型升级的首选算力,昇思成为成长最快的开源AI框架。
如果说华为是国产AI专用芯片的代表,摩尔线程作为GPU芯片头部创企,则是有望在功能上对标英伟达,成为大模型国产算力当下最佳选择。

摩尔线程去年发布第三代芯片“曲院”,以自研MUSA架构为核心,剑指大模型训练,已经布局了从硬件集群、集群管理调度平台到大模型服务等软硬一体的全栈集群解决方案,具备了千卡甚至万卡的集群能力,在集群落地方面上走在行业前列。摩尔线程率先推出了首个全国产千卡千亿模型训练平台——摩尔线程夸娥智算集群,可以为大模型训练提供稳定、高效、高兼容的算力支撑。摩尔线程创始人、CEO张建中表示,摩尔线程致力于以全功能GPU推动“人工智能+”战略实施,通过自主研发的芯片、显卡及集群解决方案,赋能各行业智能化转型。目前,摩尔线程多款产品在大模型、数字孪生、物理仿真、元宇宙等场景中发挥算力基石作用,助推金融、教育、电力、农业、能源等重点行业的数字化转型。
国产AI芯片,需要在包容中提升
在国产AI芯片面临难得的窗口期之际,加速应用部署落地成为重中之重的考验,要看到的是,促进场景落地不仅依赖硬件能力,还需要构建与硬件匹配的软件生态。生态的构建仍然是国产AI芯片绕不开的关卡。
当下,我国AI芯片公司在设计能力上在逐步缩小与海外巨头的差距,在生态层面,或走与成熟生态兼容的路线,或走自建生态之路,主旨均是为了促进场景快速落地。但无论是借力使力,还是自主搭台,与国外巨头相比仍需要“长跑”。

在AI芯片+生态的全面较量中,有效算力其实是最重要的因素,而生态在释放有效算力中发挥至关重要的作用。中国工程院院士、清华大学计算机科学与技术系教授郑纬民在公开演讲中指出,AI大模型升级的核心硬件是芯片,目前国内自研AI芯片起步较晚,但可通过生态建设实现弯道超车。
他进一步指出,如果算力生态做得非常好,即使国产芯片的硬件性能只有国外性能的60%及以上,业界也会采用。但如果算力生态没做好,新型软件跑不起来、软件移植不顺畅,即便硬件性能达到国外的120%,照样难以转变为有效算力。因而,相较于芯片本身的硬件性能提升,通过营造生态,提升国产AI芯片的“包容力”更加急迫。
但整体而言,国内AI芯片厂商由于生态建设还在构建和发展之中,国产芯片在大模型训练相关软件移植方面表现仍待加强,因此需要进一步加强底层研发,做好包括编程框架、并行加速、通信库在内的软件研发工作。
此外,还需要上下游合力攻关,让更多的智算中心、AI服务器中采用国产AI芯片,让AI芯片在真实场景中去淬炼,在应用过程中不断优化和提升也将是提升国产AI芯片竞争力的不二之选。可喜的是,国内在这方面已开始强力推进。今年2月,国务院国资委召开中央企业人工智能专题推进会,10家中央企业签订倡议书,这对于国产AI芯片来说无疑是重要的机遇。当央企开放场景,国产AI芯片才有了训练场。
以AI为代表的数字化变革大幕已然拉开,国内大模型的持续升级也推动着生成式AI技术获得广泛应用,国产AI芯片面临难得的机遇窗口期,通过从硬件性能到软件生态的持续打造和夯实,以及上下游的通力协作,全面开花、落地生根也指日可待。




