通过软件洞察和用例分析塑造的NPU IP架构


神经处理单元(NPU)的出现彻底改变了机器学习领域,使深度学习任务所需的复杂数学计算得以高效地执行。通过优化矩阵乘法和卷积运算,NPU极大地增强了AI(人工智能)模型在各个领域的能力,从服务器群到电池驱动设备。
TinyML(微型机器学习)的出现进一步推动了AI的发展,其重点是在资源有限的嵌入式设备上实现机器学习算法。TinyML的目标是在数十亿边缘设备上实现AI能力,使它们能够在本地实时处理数据并做出决策,而无需依赖云连接或强大的计算资源。
结合NPU技术基础和TinyML最新发展,Ceva推出了创新性的Ceva-NeuPro –Nano。这款紧凑高效的NPU IP是针对TinyML应用精心设计的,在性能和能效之间实现了完美平衡。Ceva-NeuPro-Nano的独特架构经过优化,能够端到端完整运行TinyML应用的整个流程,从数据采集和特征提取到模型推断,使其成为资源受限、电池驱动设备的理想自给自足解决方案。

来源 (Ceva)
设计理念:
Ceva-NeuPro-Nano的设计理念源于深入了解用户的需求和观点,我们希望提供一种功能强大且用户友好的解决方案。设计理念的主要指导思想是优先考虑软件的易用性和解决应用层面的难题,而不是仅仅关注神经网络层。这种方法确保了Ceva-NeuPro-Nano能够高效且无缝地处理神经网络、控制和DSP(数字信号处理)工作负载。
主要目标是创建一个嵌入式AI的NPU,在不降低能效的情况下提供行业领先的性能。Ceva-NeuPro-Nano的顶尖级硬件设计专门针对TinyML应用的低功耗、高效率需求进行了优化,这使得它成为资源有限的边缘设备的理想解决方案。
软件优先:
Ceva-NeuPro-Nano的综合软件生态系统支持两大TinyML推理框架:TensorFlow Lite for Microcontrollers和MicroTVM。这确保了能与各种TinyML应用无缝集成。与许多其他解决方案不同,Ceva-NeuPro-Nano不仅仅是一个依赖于主机微控制器单元(MCU)的加速器;它是一个完全可编程的处理器,具有出色的神经网络(NN)和数字信号处理(DSP)能力,这使得它能够应对未来的发展需求,并适应任何未来层级或运算操作。
除了对主流TinyML框架的支持,Ceva-NeuPro-Nano还配备了一个全面的神经网络库,用于需要手动调整模型的情况,并且提供完整的数字信号处理(DSP)功能的DSP库。这些全面的库增强了Ceva-NeuPro-Nano的适应性和多功能性,使开发者能够轻松地将其应用到各种独特的应用需求中。
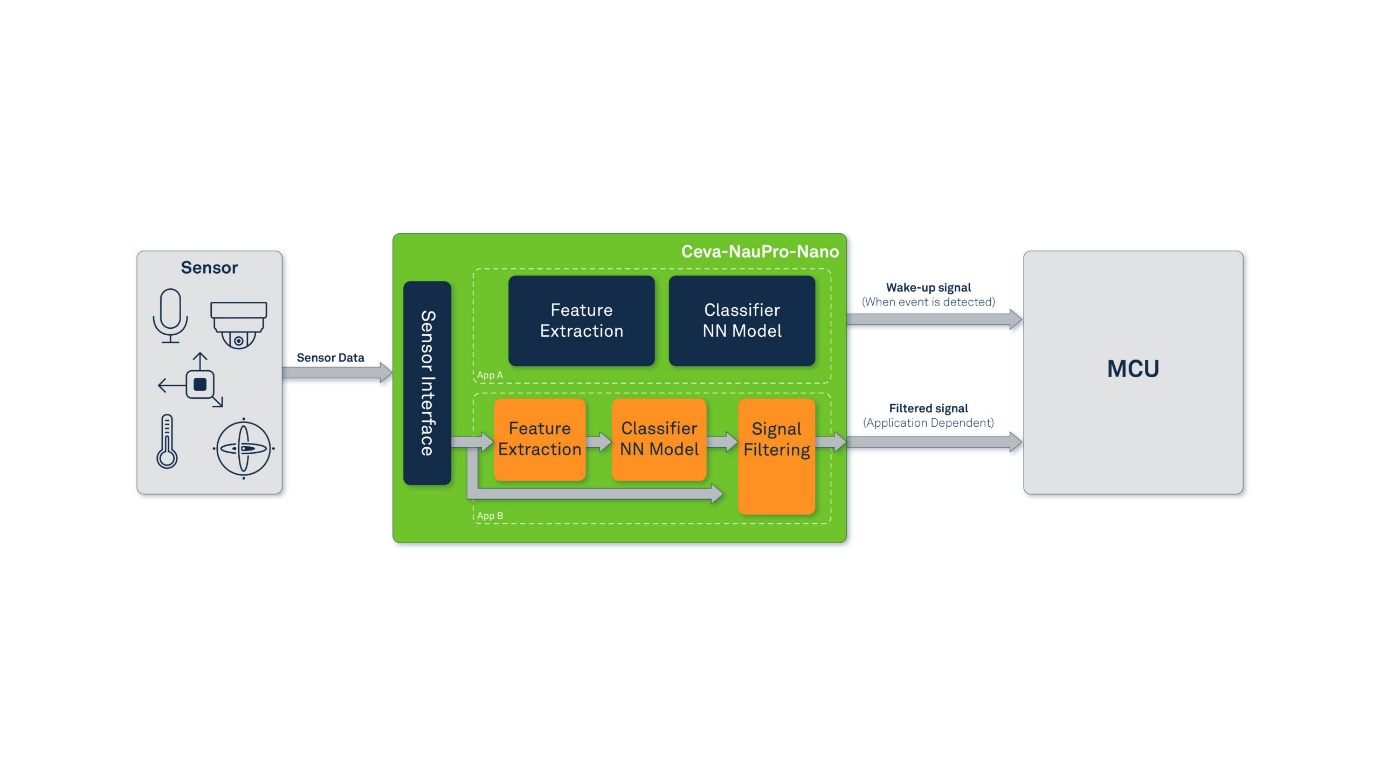
创新架构:
Ceva-NeuPro-Nano架构引入了多项创新功能,解决了TinyML应用中的关键痛点。它支持直接处理压缩模型权重,无需进行内存密集型的解压缩操作,这使其非常适合内存有限的TinyML设备。先进的数据缓存系统简化了硬件管理,提高了整体效率,消除了直接内存访问(DMA)调度的复杂性。
Ceva-NeuPro-Nano的硬件架构经过专门设计,旨在处理非线性激活,使其能够支持各种机器学习模型。它还集成了尖端节能技术,确保高效率,非常适合对功耗敏感的边缘设备。凭借对对称和非对称量化方案的硬件级支持,以及本地4位数据类型支持,Ceva-NeuPro-Nano可适应各种TensorFlow模型,进一步扩大其适应性,并实现更高效的数据处理和存储。
MAC数量大比拼
许多NPU制造商会吹嘘其设计中的MAC(乘法累加)单元数量越来越多,暗示MAC越多性能越好。然而在Ceva,我们对Ceva-NeuPro-Nano采取了不同的方法,重点关注MAC的利用率而不是单纯的数量。
我们认识到,如果不能有效利用MAC单元,那么拥有大量的MAC单元并不一定就意味着能实现更优秀的性能。事实上,MAC数量更多,往往导致功耗增加,却不会带来相应的性能提升。Ceva-NeuPro-Nano NPU有两个版本:Ceva-NPN32有32个8×8 MAC,Ceva-NPN64有64个 8×8MAC。通过大量的实验,我们证明了我们的32-MAC版本可以与其他128 MAC的解决方案相媲美。我们的创新设计和架构提高了MAC利用率,从而实现了这一卓越的效率。
在Ceva-NeuPro-Nano中,我们优先考虑MAC利用率而非简单的追求数量,因此在保持较低功耗的同时,提供了令人瞩目的性能。这种方法完美契合TinyML应用的需求,因为TinyML应用对功耗方面要求极高。我们专注于效率的优化,使Ceva-NeuPro-Nano能够在性能上超越那些MAC数量更多的竞争对手,证明智能设计和优化远比参与MAC数量大比拼更为重要。
现实使用案例:
我们进行了严格的测试和分析,将各种TinyML模型在NeuPro-Nano上的执行情况与其他解决方案进行了比较。结果突显了NeuPro Nano的惊人价值。它的面积缩小了45%,能效提升了3倍,内存消耗减少了高达80%,并且在TinyML网络性能上提升了10倍。
我们通过专注于分布在三大支柱(3 V)上的现实TinyML使用案例,实现了这些出色的性能和效率指标:视觉、语音、振动:
在视觉支柱方面,我们认识到人脸检测、地标检测、物体检测和图像分类等轻型计算机视觉任务,在可穿戴设备和物联网设备进行交互和了解环境方面发挥着重要作用。EfficientNet、MobileNet、Squeezenet和Tiny YOLO等稳健的、经过行业验证的神经网络设计,可以处理主要的轻量级计算机视觉任务,这些是我们考虑的模型的几个例子。这确保了Ceva-NeuPro-Nano能够优雅而高效地处理CNN、深度卷积和其他层次。
在振动支柱方面,我们借鉴了Ceva在IMU硬件、软件和应用开发方面的独特经验,这些经验帮助我们解决了诸如人体活动识别和异常检测等任务,这些任务在可穿戴技术和工业应用中具有重要意义。
在语音支柱方面,作为人机交互的下一个重要步骤,我们利用了自身在语音传感应用开发方面的丰富经验(如关键词检测、降噪和语音识别),以及对该领域工作的深入了解。我们考虑到从循环神经网络(RNN)和卷积神经网络(CNN)到轻量化Transformer模型等多种设计的网络,确保了NeuPro Nano设计可以驾驭各种网络结构。
在整合三大支柱(3 V)时,我们意识到了基于神经网络应用中经常被忽视的一个重要部分——特征提取的重要性。这促使我们在Ceva-NeuPro-Nano设计中集成了强大的控制和DSP功能。
结论:
Ceva-NeuPro-Nano独特的架构,高效的MAC利用率,和全面的软件生态系统使其成为一个强大的多功能解决方案。它的设计理念侧重于现实使用案例和应用层面的挑战,确保能够高效、无缝地处理各种任务。凭借其突破性的性能、效率和适应性,Ceva-NeuPro-Nano将革新TinyML领域,为数十亿资源受限的设备带来机器学习的力量。
Ceva-NeuPro-Nano成为了Ceva-NeuPro系列NPU中的一员,扩展了我们的客户现在可以处理的边缘AI工作负载范围,涵盖了从TinyML应用到大规模生成式AI模型的各种需求。




