ISEDA首发!大语言模型生成的代码到底好不好使

在大模型席卷一切、赋能百业的浪潮里,“码农”也没能独善其身。各种代码自动生成的大模型,似乎描绘了一个人人都能像资深工程师一样写代码的美好未来。
但在这个理想成为现实之前,有一个不能回避的问题—这些自动生成的代码真的有效吗?大模型也会犯错,我们肯定不希望把看似正确的错误结果交给用户,所以需要一个能精确验证模型生成答案的考官。
近期,芯华章提出了一种对大模型生成代码形式化评估的方法,称为FormalEval。它能自动化检査生成代码的质量,无需手动编写测试用例。经过测试,FormalEval不仅能够识别出现有 RTL 基准数据集中潜藏的约50% 的评估错误,还能通过测试用例增强的方式来修复这些错误。
本文共计2680字,预计阅读时间7分钟,希望能够帮助您更好了解:
如何快速验证大模型自动生成的代码?
新的方式和传统方法有什么不一样?
本文内容根据芯华章研究院入选ISEDA2024论文《FormalEval: a Formal Evaluation Tool for Code Generated by Large Language Models》梳理。感谢ISEDA评选委员会对芯华章相关研究的认可。

ISEDA2024技术分享现场
现有验证方法
要么费时费力,要么不够准确
在开始讨论前,有必要先明确这个验证系统需要具备的两个核心属性:
第一,验证结果必须是足够准确且充分的;
第二,效率也非常重要。
基于这两点,现有方法又是怎么评价模型生成结果的呢?有三种主流方式:
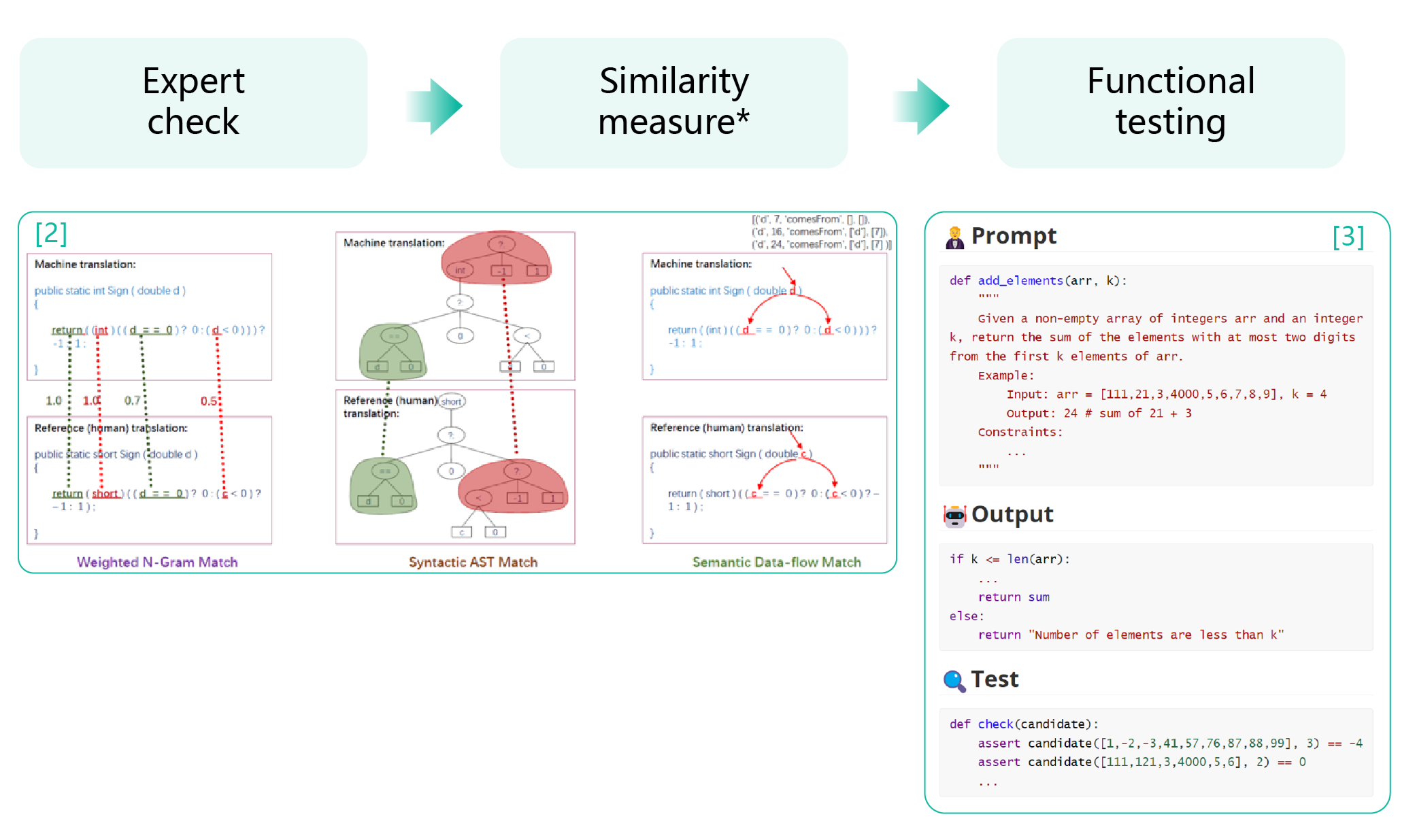 / 01 /人类专家评价
/ 01 /人类专家评价
给定问题, 大模型生成代码, 人类工程师来判断结果是否正确;
/ 02 /基于近似指标的自动化评价
给定标准答案, 有基于文本间相似度的(Rouge1), 也有基于文本相似度结合代码间结构(抽象语法树、数据依赖图)相似度的方法(Code-Bleu2);
/ 03 /基于验证平台和测试用例的自动化评价
给定验证平台, 通过对比模型在各种不同测试用例下的输出是否等于期望结果来评价模型的方法;
显然, 第一种方法的评价精度受限于专家自身的能力, 而成本也受限于专家的时间资源。
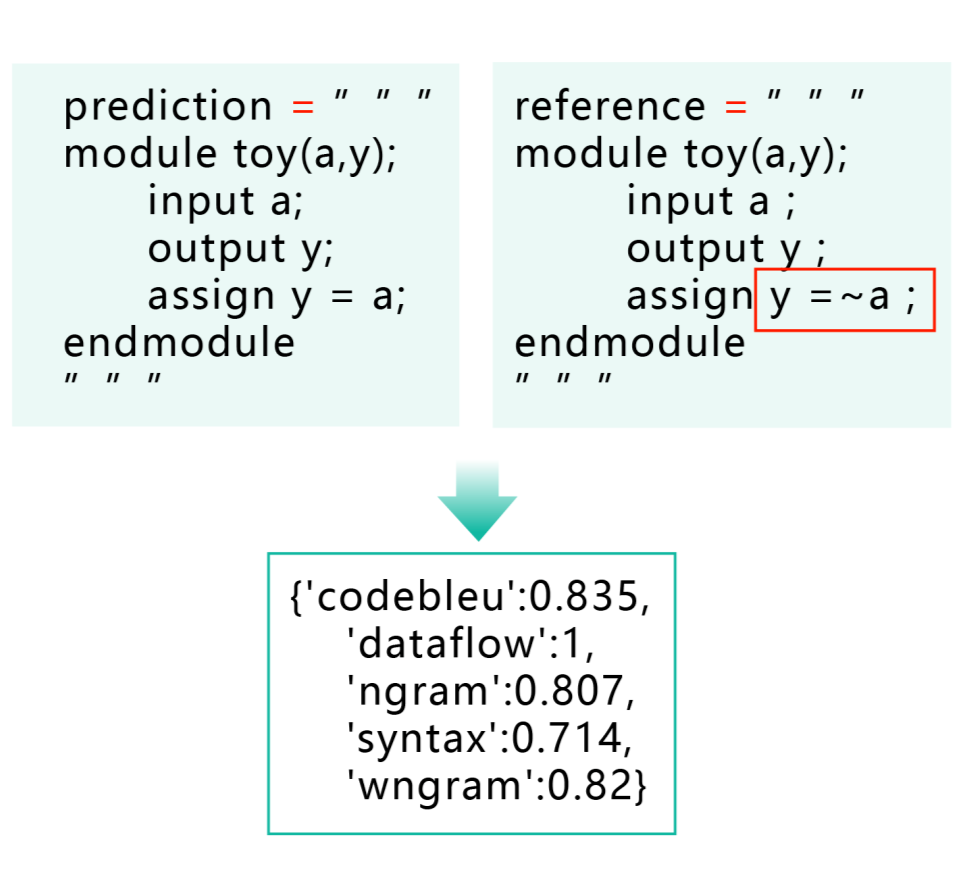
第二种方法, 虽然自动化程度高, 依赖的资源不多(只需要一份标准答案), 但因为借助的是近似指标的关系, 无法保证在指标上表现理想的模型,在功能上也能真正符合预期。从下例可以看出,明明模型生成的代码给出的答案和正例是完全相反的,但是code-bleu得分却接近1(满分),这显然是不合理的。
而第三种方法虽然准确度最高, 且在满足资源(平台、用例、仿真器、标准答案)的情况下能实现自动化评价, 但是这些前置资源的构造本身就需要花费大量人力成本(编写好的测试用例通常和编写程序一样困难), 所以该方法也无法实现真正的大规模自动化验证。我们统计了四个广泛使用的评估数据集,发现每个问题的平均测试用例量都非常少。这会导致测试不准确的现象。
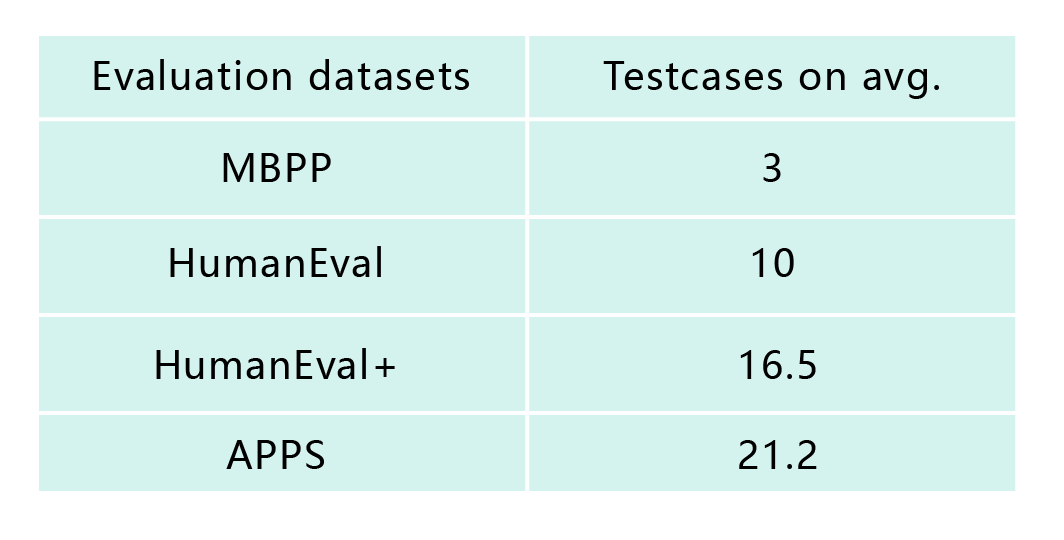 具体来说,当前最广泛被使用的是OpenAI在Codex论文中开源的HumanEval(上表第三行)。OpenAI的(HumanEval3)验证采用了第三种方法, 但仅提供了164个问题用作模型校验, 与之对应的是其提供了成百上千万行的代码资料供模型学习。
具体来说,当前最广泛被使用的是OpenAI在Codex论文中开源的HumanEval(上表第三行)。OpenAI的(HumanEval3)验证采用了第三种方法, 但仅提供了164个问题用作模型校验, 与之对应的是其提供了成百上千万行的代码资料供模型学习。
事实上,后续有学者发现(HumanEval+4上表第四行)由于平均每个问题仅包含约10个测试用例,即使只考察其提供的问题,该验证系统也不能确保生成的代码是正确的:
下图里模型能顺利通过HumanEval里的测试用例(底部),但由于其实现逻辑的问题(set是乱序的),在研究者新给出用例上(顶部)会校验失败。

从HumanEval到FormalEval
用形式化验证来替代动态仿真
基于上述方法的局限性, 芯华章提出了 "FormalEval"。
其核心思想是利用形式化的等价验证方法来替换依赖 {仿真器+测试用例+测试平台} 的功能性验证方法。
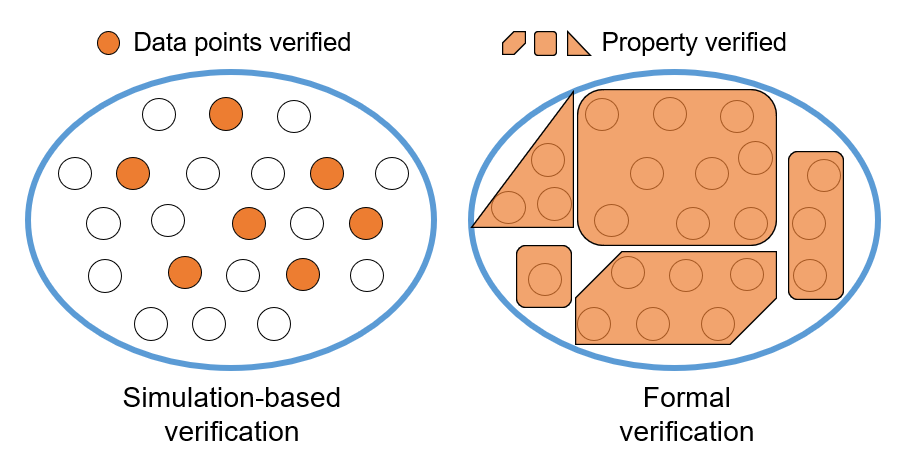
对比动态仿真验证,形式化验证能通过系统性地覆盖待校验程序的属性空间,来确保其符合规范要求(下图对比):
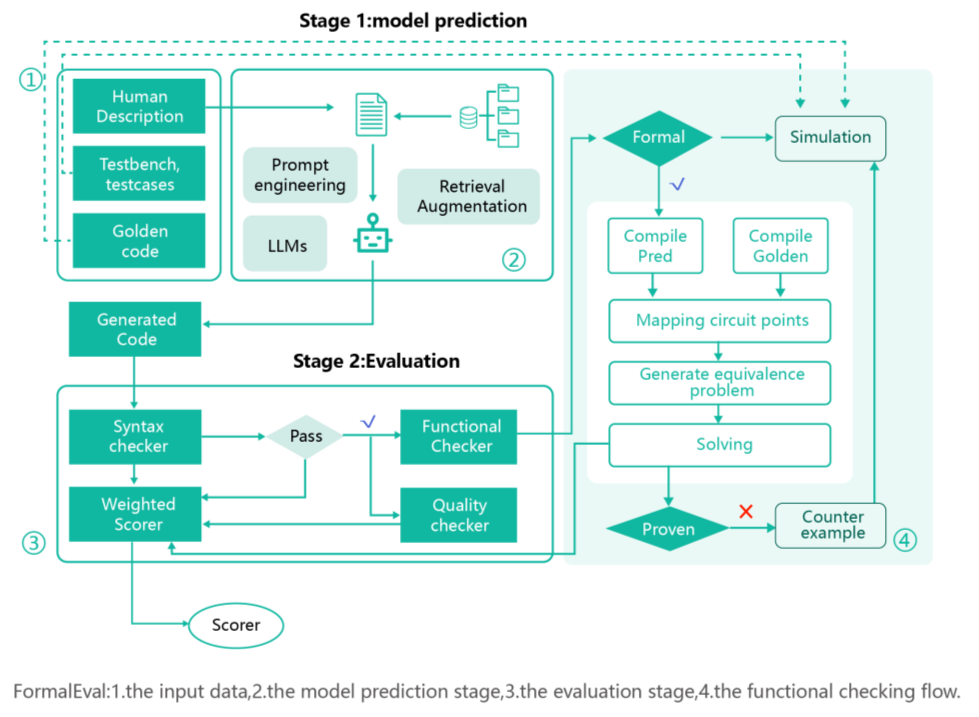
FormalEval的执行分为两个阶段。
在第一阶段里,结合“提示工程”和“检索增强”等推理技术,我们对用户的自然语言输入进行转换,然后送入大模型里生成代码。
在第二阶段里,给定一组正确标记的和模型预测的代码对,系统会从语法检查开始评估。如果检查通过,这对代码将被发送到功能检查器和质量检查器。
如下图右侧所示,功能检查器这个核心模块,我们采用芯华章自研的 GalaxEC-SEC 工具来替换传统的仿真工具,工具会给出一个 {satisfied, violated} 的二值输出作为验证结果,简单明了。
来,上FormalEval实测结果
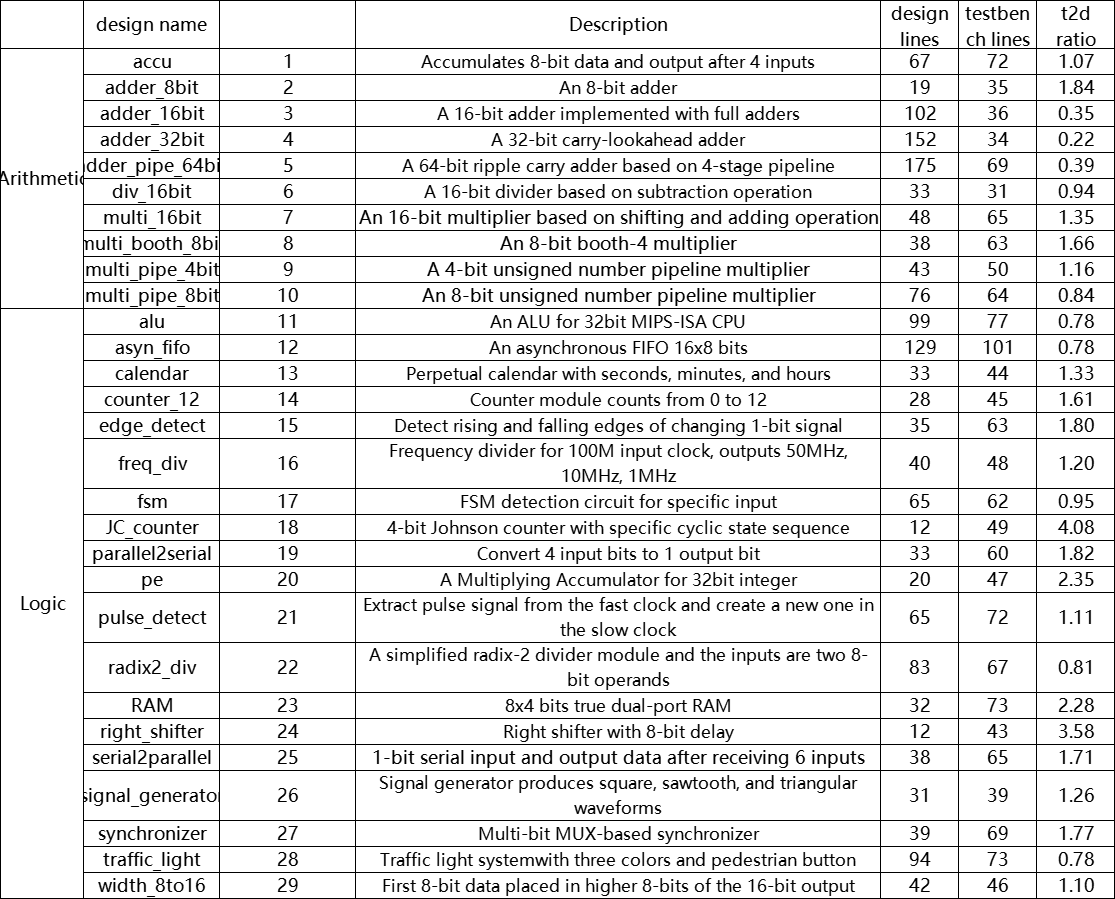
我们挑选了一个基于电路设计的数据集(RTLLM5)来验证FormalEval,该数据集里包含了难度不一的28个设计及对应的仿真测试平台。我们分别要求GPT-4 和 GPT-3.5针对每个设计规范生成5个候选答案,再提交给仿真测试平台和FormalEval来检验。
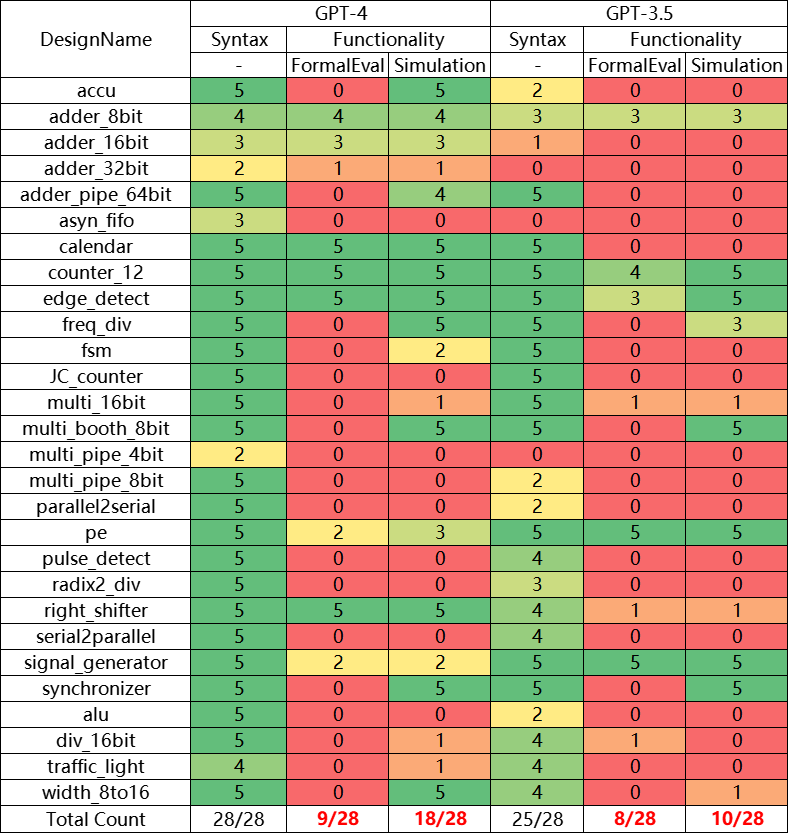
汇总检验结果会得到如下表格,可以看到虽然语法校验能排查掉一部分的错误,但依然存在很多通过了语法校验但功能性检查失败的生成代码。
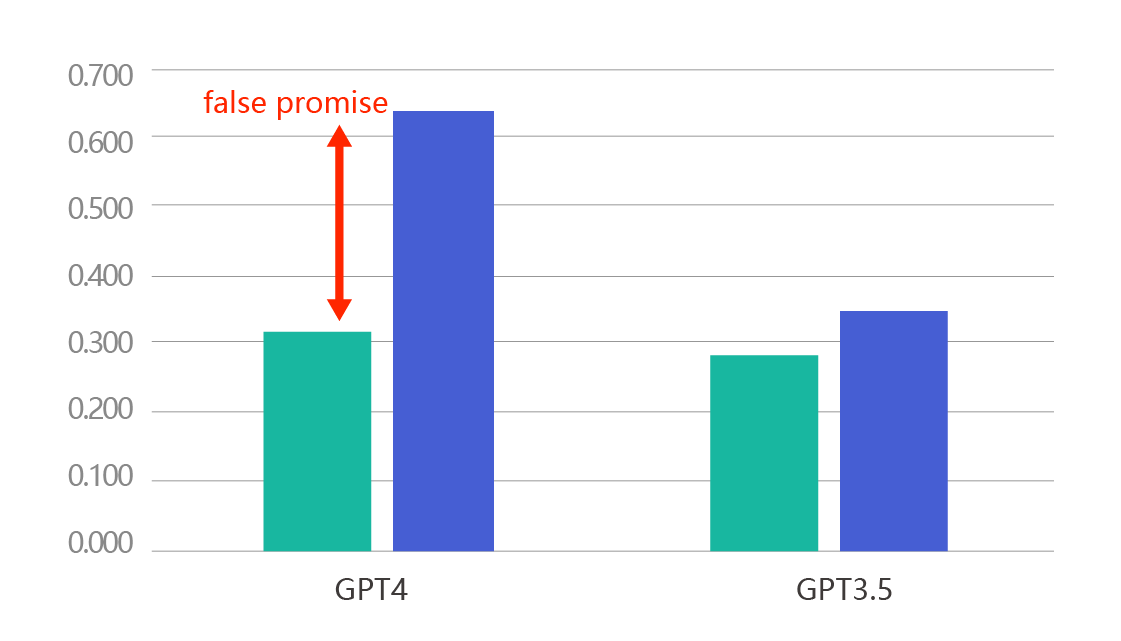
单独对比功能性检查的结果,可以看到FormalEval对GPT4的精度打分只有0.32,而原仿真测试则给出了0.63的高分。这是因为原仿真测试不能有效识别大量的错误结果。那这个比例有多高呢?
通过逐个分析FormalEval给出的错例,我们可以确认原仿真测试工具给出了超出真实案例100%的假阳性评分,这是非常具有误导性和危险的。
同时,因为FormalEval无需人工编写测试用例,我们可以方便地翻倍原测试数据,以确保模型在不同测试数据集上的一致性表现。
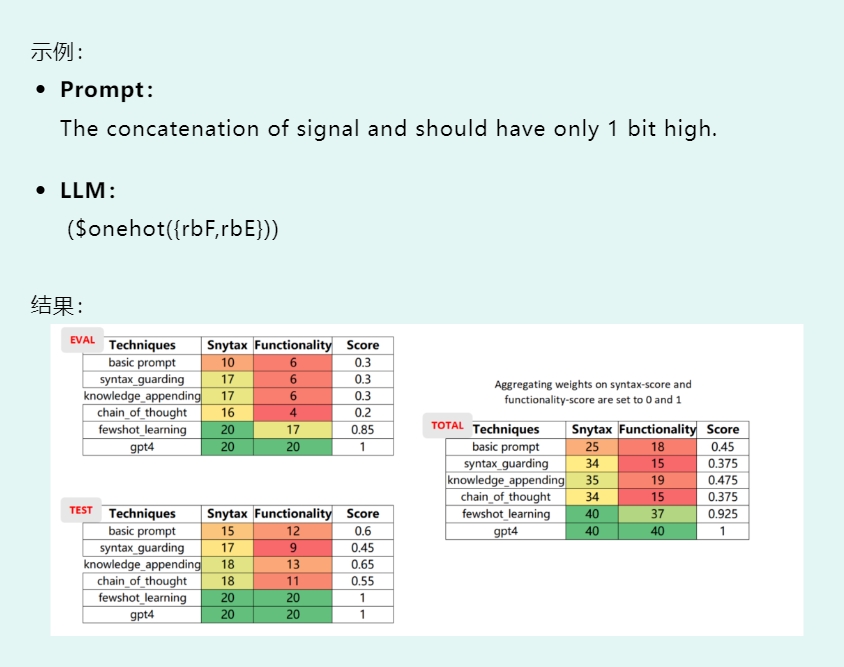
当然, 等价性校验除了在评估模型时至关重要,在提示技术选择、数据自标注、模型性能提升、线上推断时也都有广泛的使用场景。
而且,除了等价性校验,形式化方法学里的另一大分支模型检测技术也能够被应用在大模型产品里。
以上这些方面,芯华章的工作也正在进行中。
总结
近年来大模型彻底颠覆了学界里AI的研究方向,基于大模型的各种应用也如雨后春笋般涌现,但要真正形成成熟的产品,大模型的幻觉问题和输出不可控问题等都是不得不解决的挑战。
拥有一个准确、自动、高效的验证工具能够保证您的应用在用户侧安全,稳定地输出符合预期的结果。如果您对FormalEval这款工具感兴趣,欢迎点击阅读原文,申请下载论文全篇内容,我们将与您取得进一步联系。




