V-Tech | 为旌星图工具链部署SwinT模型,降低视觉Transformer计算成本


从Transformer到SwinT
Transformer算法最初是为自然语言处理任务设计的,因其注意力机制的独特设计,使得模型能够捕捉到全局和局部之间的复杂关系,因而计算机视觉领域一直尝试将其引入。
2020年,DETR算法成功将CNN与Transformer相结合,构建了一个端到端的目标检测模型。同年提出的ViT算法,创新性地将图像划分成一个个patch,并将每个patch展平为一个向量,使得图像数据转化为序列化数据,之后输入到Transformer模型中,实现了Transformer在图像分类任务中的应用。ViT算法相比于DETR算法,摒弃了以CNN网络为backbone的做法,从输入图像下手,将其转变为序列数据,基本无需改动Transformer便可实现图像分类网络。这种处理方式,也给后续许多算法提供了新思路。
但ViT依旧存在局限性,由于计算量与像素数量的平方成正比,对于高清图像,计算量陡然上升。
为解决上述问题,诞生了SwinT(Shifted Windows Transformer)。该算法的主要设计思路围绕以下两点展开:
模仿CNN算法的卷积操作,提出一种滑动窗口机制,通过不重叠的local-window和重叠的cross-window,将Transformer的全局注意力计算限制在一个大小固定的窗口之中。
加入下采样的层级设计,从而逐层扩大感受野范围,使得被限制在窗口范围内的注意力计算也能获取全局的特征信息。
由于引入了类似CNN卷积的操作,再加上多层级的下采样结构,SwinT既具备了较强的局部信息聚合能力,又保留了Transformer无需过多操作便能捕获远距离特征信息的特点,因此,算法表现极为出色,既能够作为Transformer类型算法在计算机视觉领域的通用backbone,又能在一定程度上能代替CNN。
SwinT算法原理
网络主体结构
SwinT网络结构,由Patch Partition和4个Stage组成。Patch Partition将输入图像转换成patch size为4的众多patch。每个Stage包含一个Linear Embdding或Patch Merging,以及若干STB模块(Swin Transformer Block)。在Stage1中先通过Linear Embedding将众多patch嵌入到高维向量中,即把通道数调整为C,之后送入STB。Stage2-3,均为先由Patch Merging进行下采样,缩小特征图的分辨率,扩大感受野范围,然后送入STB。
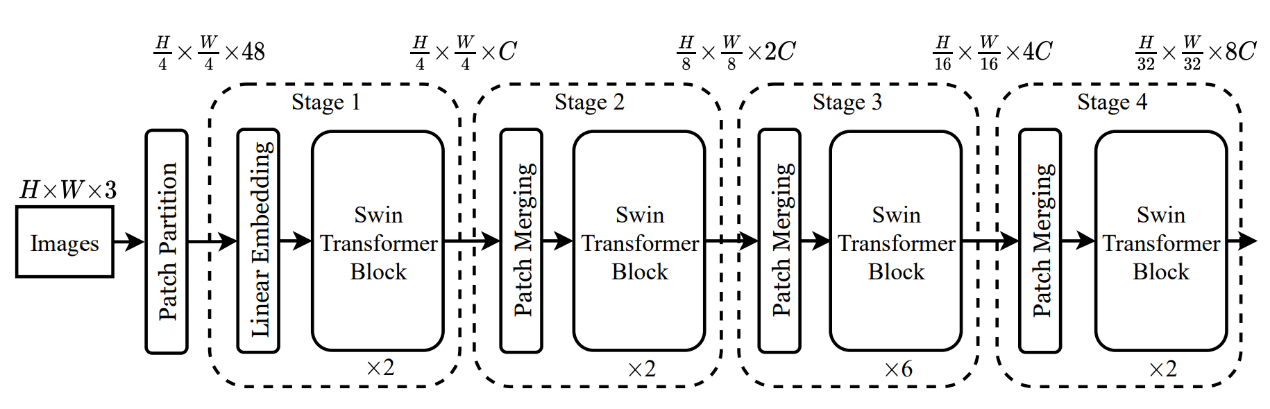
SwinT架构
Patch Merging
在CNN中,通常会使用卷积层或池化层进行下采样操作,而SwinT的下采样操作相对复杂,每次下采样均为两倍,因此在H/W方向上,均是间隔2选取元素,得到四个宽高为(H/2,W/2)的tensor,通过将这四个tensor在c通道方向堆叠,形成一个新的tensor后,经过Linear层,最终获得下采样输出。

Patch Merging流程
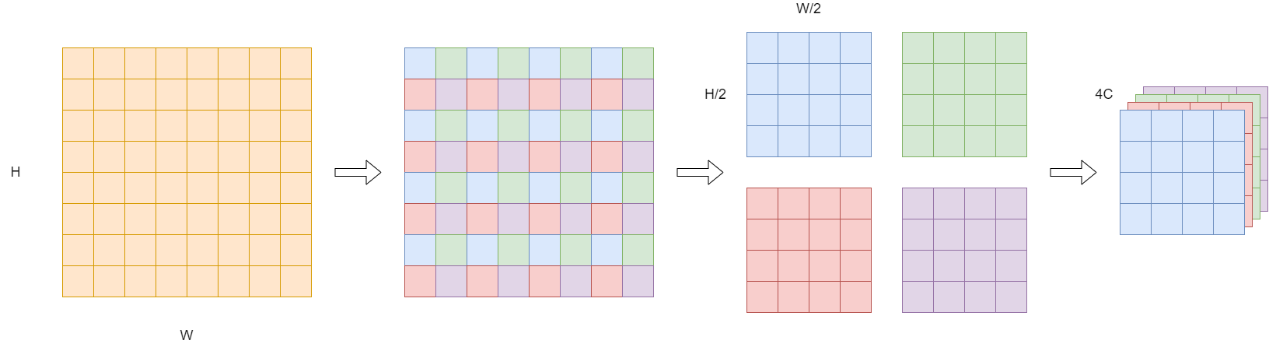
tensor维度变化
STB模块
STB模块是SwinT中最核心的部分,其在标准的Transformer自注意力基础上改进为窗口自注意力(W-MSA:window multi-head self-attention)和移动窗口自注意力(SW-MSA:shifted window multi-head self-attention)两种结构。这两种结构是成对使用的,其中:
W-MSA将每一个window范围当作独立的全局进行自注意力计算,从而降低计算量;
SW-MSA则把window偏移一半边长后计算window范围内的注意力,使得相邻window内的元素产生交互,进而实现特征信息融合。
这种通过window移位实现不相交window内数据聚合的方法,有效提升了各类计算机视觉任务中的计算效果。
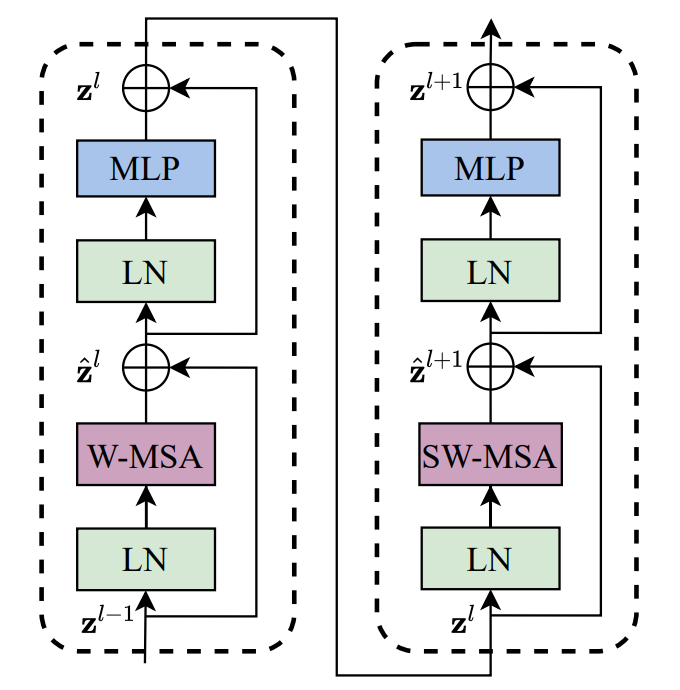
STB结构
需要说明的是,SW-MSA部分由于对window进行了移位操作,使得计算量增加。以下图为例,左边进行的是W-MSA操作,此时只有4个window需要进行内部的注意力计算。在SW-MSA操作中(右图),window偏移了一定距离后,出现了9个大小不统一的window需要进行注意力计算,这势必会带来额外的计算开销。
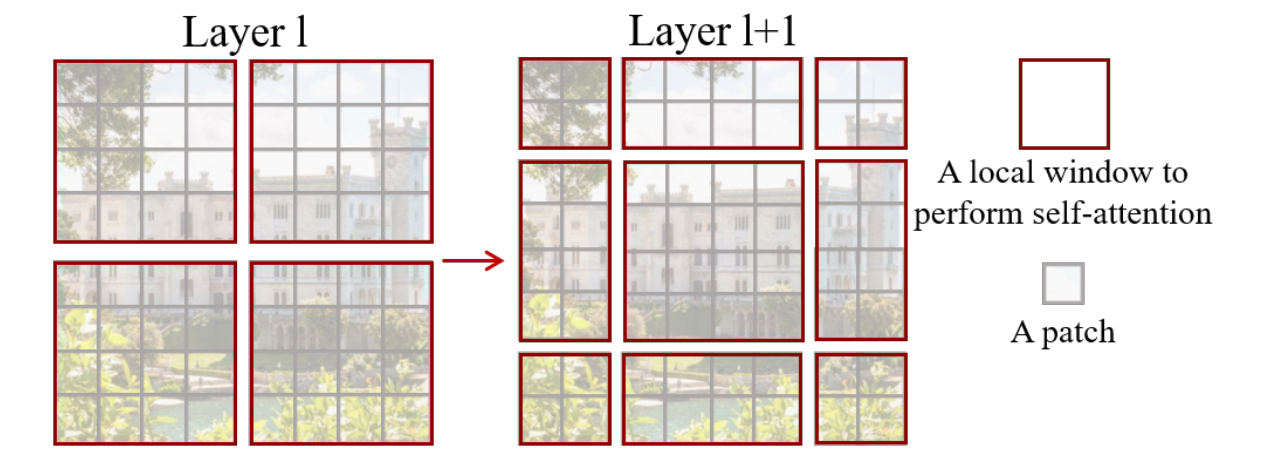
对于移位引起的计算量增加,SwinT采用了cyclic shift和attention mask的方案来解决。
cyclic shift通过按照一定规律移动feature map,将window移位后产生的9个计算区域,重新拼接成4个区域,使得计算量和W-MSA保持一致。首先,将顶部数据(序号1-4)移动到底部,再把最左侧数据(序号5、9、13、1)移动到最右侧,得到result feature map。
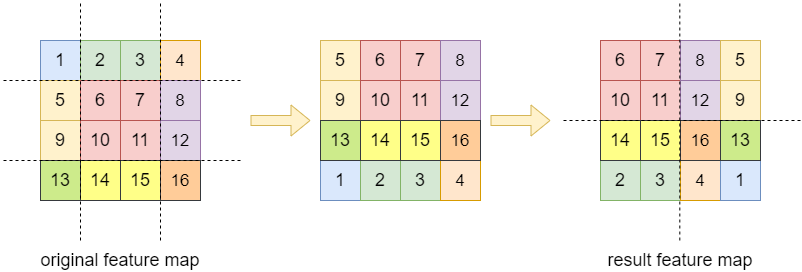
result feature map中的4个区域,除左上角区域没有变化,其他区域都由原本相距很远的数据拼接而成,这部分数据本不应参与所处区域的注意力计算,故要对其进行屏蔽,即使用attention mask来掩盖住不属于本区域的数据,得到注意力结果之后再把移位区域平移回去。
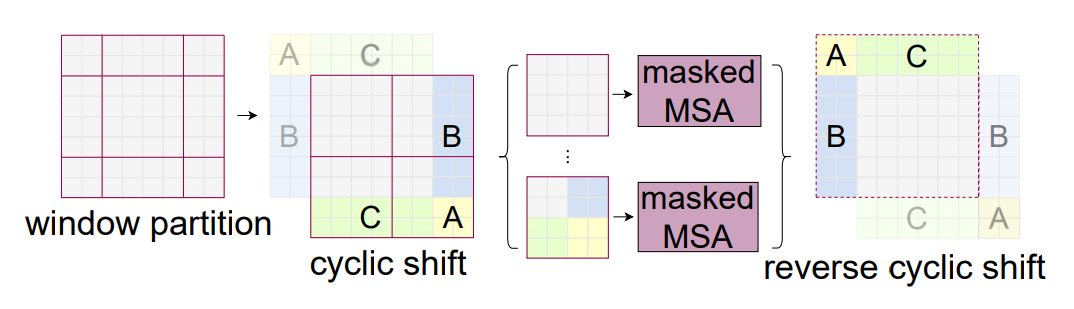
cyclic shift+attention mask解决移位计算量增加问题
SwinT模型导出Onnx及量化
为旌天权TMNPU是一款专为深度学习算法优化加速而设计的硬件单元,其广泛兼容并支持当前主流公开的神经网络以及各类常见算子,涵盖了深度学习卷积神经网络和Transformer网络。为旌星图TM工具链针对为旌全自研天权NPU硬件平台开发,充分利用为旌天权TMNPU所特有的高集成度自定义指令集,从而确保深度学习网络模型能够得到高性能执行。
在模型部署过程中,为旌星图TM工具链要求待部署的模型格式为Onnx,即非Onnx格式的原模型需要先进行转换,下文以pytorch模型为例。
Onnx模型导出
pytorch模型一般以源码+参数文件的形式保存。作为示例,本文一同使用的torchvision中的模型也是以上述形式保存。
环境准备
首先是确保pytorch和torchvision已安装且torchvision的版本在0.13以上。请注意python、torchvison和pytorch之间的版本存在约束关系,具体请参考https://github.com/pytorch/vision。本文在python3.8和cuda11.7的环境中安装pytorch2.0.0和torchvison0.15.1,使用如下命令:
pip install torch==2.0.0 torchvision==0.15.1
如软硬件环境不同,请参考https://pytorch.org/get-started/previous-versions/选择命令安装。
torch模型准备
使用torchvision中的SwinT模型,注意需要加载预训练参数。命令如下:
import torch
import torchvision
weigths = torchvision.models.Swin_T_Weights
model = torchvision.models.swin_t(weights=weigths)
model.eval()
转换Onnx
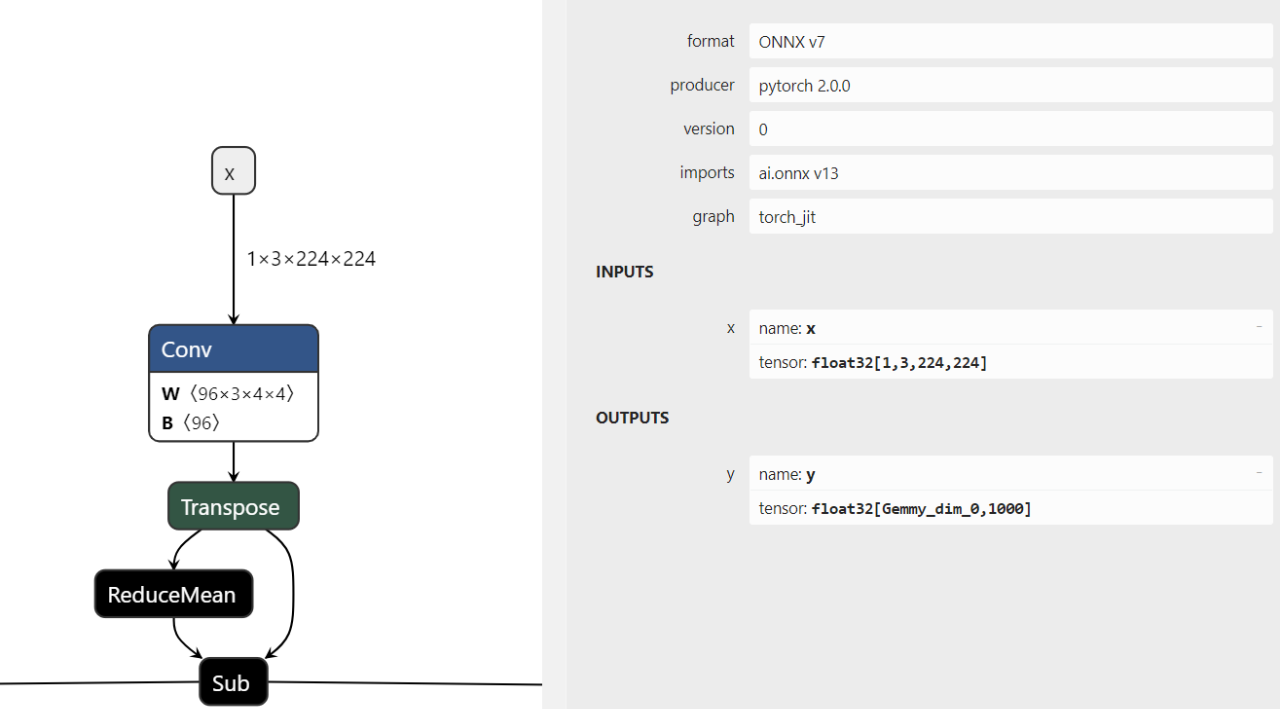
从torchvision官网的介绍中我们可以看到该模型是一个基于imagenet数据集的分类模型,该模型只有一个输入和一个输出。
设置输入名称为"x",输出名称为“y”,输入的shape为[1,3,224,224];设置模型的存储文件名为swin_t.onnx,opset_verion为13。综上,使用如下命令即可导出Onnx模型:
shape = [1,3,224,224]
x = torch.randn(size=shape)
save_path = 'swin_t.onnx'
input_names = ['x']
output_names = ['y']
opset_version=13
torch.onnx.export(
model, x, save_path, input_names=input_names, output_names=output_names, opset_version=opset_version
)
上述代码运行之后,得到swin_t.onnx。该文件可用netron工具打开。
更多具体转换教程可以查看此网址:https://pytorch.org/docs/2.0/onnx.html。
模型量化
模型清洗
我们把开发环境切换为旌星图TM工具链的开发环境。
此前转换出的Onnx模型中并不能直接使用,因为工具链不支持动态算子(比如shape)、分支和循环,另外本身模型中还有很多待优化的地方。使用onnxsim可以进行常量折叠、算子融合、死代码消除等操作。onnxsim的命令如下:
onnxsim swin_t.onnx swin_t_new.onnx
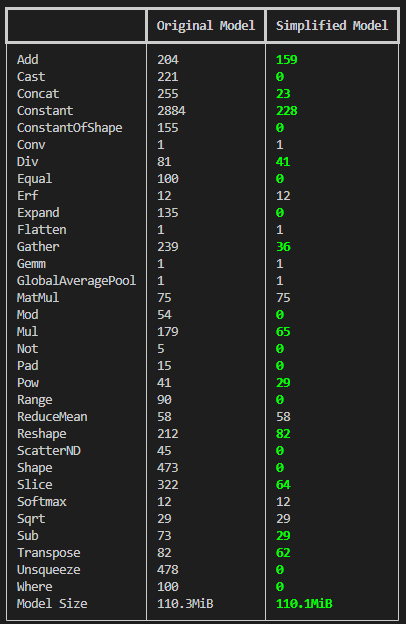
得到swin_t_new.onnx之后,推荐再使用OnnxConvertTool命令进行模型清洗,该命令可以将Onnx模型中一些不支持的结构(比如不对称pad的卷积和池化算子)转为支持的结构,也会将模型的一些算子和参数替换为等效的算子和参数。该命令如下:
OnnxConvertTool --input_model swin_t_new.onnx --output_model swin_t_washed.onnx
使用该命令,我们最终得到swin_t_washed.onnx,作为量化用的模型。
PTQ
在运行ptq之前,我们需要准备数据集。下文仅作演示,我们从imagenet数据集中随机抽取了20张图片作为校准数据集,并放在名为imagenet_demo的文件夹下。
在imagenet_demo的同级目录下,新建config_ptq.yml,内容如下:
model:
onnx_model: ./swin_t_washed.onnx
work_mode: PTQ
quant:
activation:
observer: MinMaxObserver
dtype: int8
symmetry: True
weight:
observer: MinMaxObserver
dtype: int8
symmetry: True
per_channel: True
dataset:
calibrate:
root: ./imagenet_demo/
calibrate_num_sampler: 20
batch_size: 1
transform:
resize: [256, 256]
crop: [224, 224]
out_dir: ./swint_quant_out
运行如下命令启动ptq量化:
StatlasQuant --quant_cfg config_ptq.yml
量化完成之后,在当前目录下找到swint_quant_out文件夹,可以看到该文件夹产生了一个deploy的Onnx模型以及量化参数表,这两个文件可供后续的编译器使用。
$ tree swint_quant_out/
swint_quant_out/
├── swin_t_washed_deploy_model.onnx
└── swin_t_washed_quant_param.yaml
经过以上步骤,原模型转Onnx并量化的工作完成。转换得到的量化参数表和Onnx模型会继续进入编译器,通过编译生成megrez文件,该文件可以通过runtime工具在芯片上运行该模型。
关于编译器与runtime工具我们将在后续的文章中详细介绍。
小结
SwinT在机器视觉领域中表现出了出色的性能,通过将输入图片分割成小块,并进行自注意力计算,实现了高效的图像特征提取。
除本文重点介绍的SwinT外,为旌全自研天权NPU广泛支持已公开的主流神经网络模型以及各类常见算子。配套的为旌星图TM工具链旨在帮助用户将神经网络模型高效、快速地部署到为旌天权TMNPU上进行加速处理,有效缩短客户的开发周期。通过整合端到端的解决方案,企业可以更加专注于业务逻辑与模型创新,而无需过多关注底层基础设施和运维难题,从而加速AI技术驱动的业务转型和升级。




